
自然言語処理(Natural Language Processing:NLP)を約30年研究し続けているYahoo! JAPAN研究所の颯々野(さっさの)は、前職ではメーカーの研究所に所属し、ソフトウエアや社内向けシステムの開発にも約15年取り組んできました。
ですが、「研究内容を自社の商品やサービスに反映し、研究を継続し続けることはとても難しい」と言います。
「研究がサービスに反映されるまでのサイクル」の改善に取り組んでいるという颯々野に、サービス担当者と研究者がスムーズに連携し続けるために必要なことを聞きました。
- 目次:
- 研究内容をサービスや製品に反映し、維持し続けることは、実は難しい
- 研究した技術をサービス側に渡す方法を大きく変えた
- 研究をサービスに反映し続けるための仕組みづくりに年月を費やした
- これからも研究者兼、エンジニアであり続けたい

Yahoo! JAPAN研究所 上席研究員。言語処理分野の研究開発を行っている。博士(情報学)。 大学時代から現在にいたるまで約30年、自然言語処理(日本語処理)のプログラムを開発しながら研究を進め、論文を書いている。
2006年にエンジニアとして入社しました。研究者としてではなくエンジニアで入ったのは、「自分の研究内容をサービスで実際に使われるところまで進めたい。そのためには研究一辺倒では駄目だ」という思いが強かったからです。
その後、2007年にYahoo! JAPAN研究所ができたタイミングで、初期メンバーの1人として言語処理の研究員になりました。
研究内容をサービスや製品に反映し、維持し続けることは、実は難しい
私は、自分の研究で少しでもサービスが良くなり、そして会社の利益やユーザーの便利につながってほしいと思っています。そのためにも、この数年は「研究がサービスに反映されるまでのサイクル」をどのように改善したら良いのかを考え続け、取り組んでいます。
みなさんがイメージする一般的な企業における「研究」は、
・その分野の実験を繰り返す
・実験結果について論文を書き発表する
・所属している企業の中で、研究内容を商品やサービスに反映していく
というものではないでしょうか。
実は、研究内容を実際にサービスや製品で使ってもらうためには、さらに多くのステップがあります。
また、商品やサービスをつくっている担当者たちの立場で考えると、たとえば売上目標やサービスの公開(リリース)スケジュールが決まっていることがほとんどです。さらに、予算や人が足りないなどの課題も抱えているわけです。そのため、研究内容を商品やサービスに反映することで「売上はいくらになるか」「使えるようになるまでどれくらい時間がかかるのか」などの多くの条件をクリアする必要があります。
ですが、それらすべてをクリアするまで待っていたら、研究者にとってもサービス側にとっても「遅すぎる」んですね。
研究内容をサービスや製品に反映する上での課題
研究者:
研究が反映されるまでに時間がかかる
サービス側:
研究を反映してもすぐに売上が上がるとは限らない
研究は、サービスや技術に一度反映したらそこで終わりではなく、その後も研究を続けて改善し続ける必要があります。そのためには、研究者側とサービス側の双方にとってWin-Winであること、そして、その研究とサービスに関わっている人全員が納得した上で進められる仕組みにならなっていないと、研究をサービスに反映し続けることは難しいと思っています。
また、私たちの研究所でつくった技術をサービスに反映し、その後も引き続き、プログラムや機械学習モデルの更新や仕様変更などがあった際にサービス側のプログラムを少し変更したり入れ替えたりしてもらうこと、課題のフィードバックをサービス側からもらい続けること、などは、私たちだけではできません。
以前、あるサービスのリニューアルに関わったとき、機械学習を使ったシステムを目玉にしたいと考えて、サービス側の人たちも一緒にデータ作りに取り組みました。ですが、リニューアル後には担当者がいなくなってしまったなどの理由から、その後のアップデートが止まってしまったことがありました。
同じ社内とはいえど、研究所の研究員としてサービスに関わると、一緒にサービスをつくったというより「研究所からもらった技術をサービスに入れた」という形になってしまう。これは、私が望んでいるサービスとの共創ではありませんでした。
そのようなこれまでの経験から、「自分の研究内容をサービス側に渡して作ってもらう」進め方自体を変えたいと考えたことが、この取り組みにつながっています。

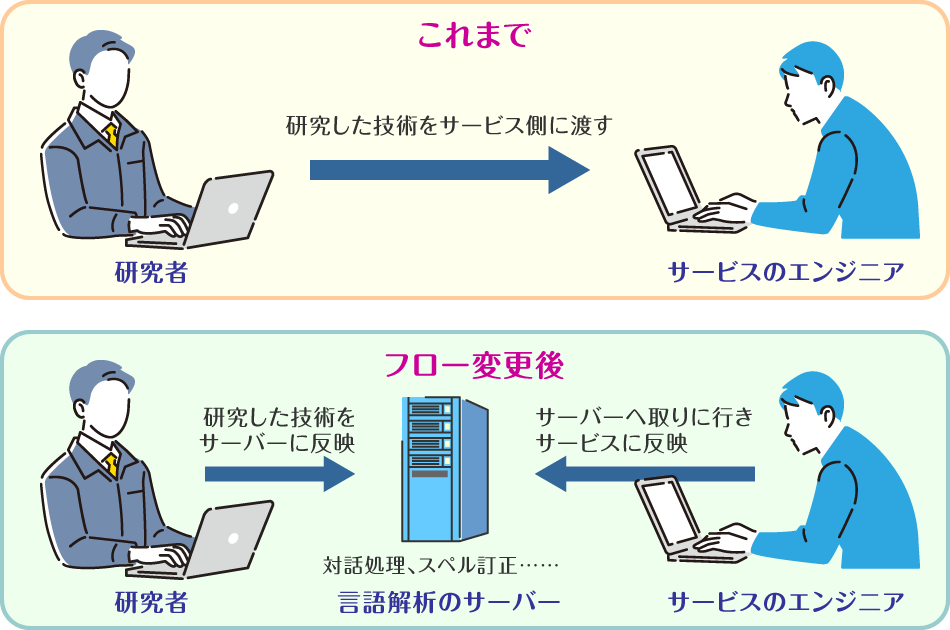
研究した技術をサービス側に渡す方法を大きく変えた
これまでは、研究開発の成果をサービスに反映するためには、たとえば言語解析ライブラリをサービス担当者に渡して組み込んでもらう、という方法を多くとっていました。ただ、この方法では、どのようなデータがより使われているのかなどを私たち研究者は把握することができず、その都度サービス担当者に利用情報がわかるデータを共有してもらう必要がありました。
そのため、これまで渡していた部分をウェブ通信でやりとりする方法を取り入れられないかと考えました。これは、私たちが言語解析のサーバーを立てておいて、サービス側は言語解析が必要なときにこのサーバーから呼び出して通信するという仕組みです。
具体的には、たとえば同じサーバーに「対話処理」も「スペル訂正」も同居するような仕組みにしました。そして、言語処理のインターフェースを共通にすればサーバーごとの違いがなくなり、サービス側の人に説明するときにもシンプルになり、わかりやすくなると考えました。たとえば「エラーの何番が返ってきたらどういうエラーなのか」「入力はこの形式の変数で与えてほしい」など、サービス側の処理がシンプルになります。
参考)言語処理API共通化の取り組み ~インターフェース共通化
メリット
・複数の言語処理機能を共通のインターフェース、システムで提供できる
・共通化することで、開発・運用・利用の際のコストを減らせる
・システムの構成・監視・運用 → 全部一つでよい
・ノウハウや改善、マニュアルなどすべて一つにまとめられる
・脆弱性対応なども1回で全て完了
・システム周りの改善も全APIに即時に反映できる
すでに稼働していた対話処理のウェブ API サーバーを拡張し、共通のインターフェースでいろいろな機能を足せる仕組みを入れました。その後、エンジニアにスペル機能などを入れてもらいながら、共通のインターフェースに統一していきました。
その当時、Yahoo!トラベルのホテル検索で、表記揺れや誤りをスペル訂正機能で訂正したいという要望がありました。私と同じ自然言語処理の研究者の鍜治(かじ)がスペル訂正機能本体を担当し、私は共通化の仕組みを仕上げて、共通化全体の仕組みとスペル訂正機能をつなぐ部分をエンジニアにサーバーに反映してもらいました。そこまで約2週間で完成しました。
現在は、細かいライブラリも合わせると約20の機能が1つのサーバーにまとまっています。サービス側は、このサービスから必要なものを引けばよく、共通の仕様になっているため運用負荷をかなり減らせていると思います。
また、対話処理、地名の解析、スペル訂正などの「プラグイン(※2)」を差し換えて使えるようになっており、研究している私たちにとっても、自分の技術をより多くのサービスで使ってもらえる可能性が広がります。
※2 プラグイン:
ソフトウエアに機能を拡張するために追加するプログラムのこと
このサーバーは、各チームから1人または2人出て順番にメンテナンスを担当しながら維持しています。どれくらいのデータを処理しているのかもわかるので、毎月のAPI利用量を部のメンバーに報告しています。「これくらい膨大な量のクエリを処理した」と具体的な数字で伝えることで、特に運用を担当している人にとってはモチベーションになると思っているからです。
研究を通じてサービス化していくということの難しさは、人の面でもあると思っています。
運用業務を若手にやってもらうことも多いのですが、この仕組みを使うことで、運用業務の複雑さをなくすことができます。そして、この方法でサーバーを運用することで、サービスにどのように貢献しているのかを実感してもらえればとも考えました。
研究をサービスに反映し続けるための仕組みづくりに年月を費やした
この仕組みを構想し作るまで、約3年かかっています。今ではヤフーで検索される全ワードのクエリを毎日処理する規模にまで大きくなりました。
私が研究者として過ごしてきた年月が長いからこそ、「今後も研究をサービスに反映し続けるためにも、3年という時間を使ってでもこの仕組み作りに取り組むべきだ」と思えたのかもしれません。
実は、その研究がユーザーに使ってもらえるサービスに反映されるまでの工程の中では、(研究につながる)種の研究や研究開発は割合が小さいんですね。だからこそ、研究をサービスに反映し続けられる仕組みや道筋をつくらないと、たとえば技術のトレンドが変わっても続けていくことが難しくなってしまうのではないかと思いました。
現在は、このサーバーのクラスタ(※3)の増強に取り組んでいます。さらに、このクラスタをもう1つ用意したいと言われたらすぐできるように、このクラスタ用のソフトウエアも整備しています。2系統にすることで、新しい仕組みを別サーバーで試すことも簡単にできるようになります。
※3 クラスタ:
複数のサーバシステムを連携することで、1つのシステムとして運用するシステムのこと
この仕組みにしたことで、たとえば「サービスの大規模キャンペーンでユーザーからのリクエストが100倍になるかもしれないので、予備のリソースを確保してほしい」と言われても、問題なく運用できるようになりました。
また、今後はライブラリ(※4)も統一しようと進めています。このAPIになって、入力の渡し方、エラーの返し方は基本一緒になっています。そのため、通信するときと同じ形でリクエストをつくって呼べば結果が返ってくるライブラリにしようとしています。
※4ライブラリ:
汎用性の高い複数のプログラムを、再利用可能な形でひとまとまりにしたもの
これまで、多くの仕組みを共通化してきました。進めていくときには、「本当にうまくいくか?」を具体的に、そして客観的に考えることを徹底しています。「いい機能だから使われるはず」は、どこか希望が入っていますよね。
「きっと先方は使ってくれるだろう」
「あまり大きな売り上げにはならなくても(研究で生まれた技術を)使い続けてくれるだろう」
などの楽観的な仮定を除いた上で、現実的なことを想定しながら、頭の中でシミュレーションを繰り返しています。また、2つ以上の課題が同時に解決できる方法はないか、ということも、よく考えています。
これからも研究者兼、エンジニアであり続けたい
研究の面では、日本語特有の課題にしっかり取り組むことも意識しています。世界の自然言語処理の研究ではどうしても英語が中心になっています。そのため、日本語の処理の改善は使命感を持って取り組んでいる研究のひとつです。
英語の処理の場合と異なる日本語の課題には、具体的には「単語の区切り」や「表記の揺れ」があります。これらの課題に対して、ヤフーのデータの強みをうまく活かしたいと考えています。
日本語解析システムの多くは、辞書やデータベースとセットになっています。それはどういうことかというと、ユーザーが入力したテキストの中に、ある飲食店の名前が入っているかを調べて、入っていれば飲食店の情報を表示するというものです。
たとえば、「喜多方 ラーメン」「旭川 ラーメン」はそれぞれ「喜多方ラーメン」「旭川ラーメン」など、ご当地ラーメンの特徴をあらわすカテゴリのように使われています。
ですが、「六本木 ラーメン」の場合は「六本木駅の近くにあるラーメン店を調べたい」というニーズの可能性が高いと予想されます。
このように、同じ「地名」と「ラーメン」の組み合わせの言葉でも、ユーザーが求めているのは「旭川ラーメンというジャンル」なのか「旭川周辺にあるラーメン屋の情報」なのかを理解して情報を表示する必要があります。

また、「旭川 ラーメン」がどのサービスで入力されたかにもよります。たとえば、地図を使っているときだったら「旭川周辺にあるラーメン店」を求めているユーザーが多いのではないか、検索であれば「旭川ラーメンはどのような味のラーメンなのか」を知りたいユーザーなのではないか、など、実際にクリックされた情報も得ながら、サービスを改善していきます。
ヤフーには「このキーワードで検索したときはこの商品を買っている人が一番多い」という膨大なデータが日々蓄積されています。そして、実際に買われているものを優先して表示する、というようにサービスに反映すればいいわけです。
たとえば先ほどの「旭川ラーメン」の例では、その商品そのものの結果がよくクリックされて、多くのユーザーが買っているのであれば、商品としての「旭川ラーメン」が求められていることがわかりますよね。
このように、その言語が入力されたとき、何が求められているかをデータで知ることができることがヤフーの強みです。ですが、今後の技術の転換点も踏まえて、自分たちもサービス担当者に近い感覚を持っていないと、研究のスピードが落ちてしまうかもしれません。
今回私がつくった仕組みを使うことで、研究の内容をサービスにスムーズに反映することが可能になりました。また、ヤフーの研究者がリアルタイムでデータを追いながら研究を続け、さらにサービスを改善し続けることも可能です。
Yahoo! JAPAN研究所の研究をサービスに反映し続けるためにも、私はこれからも研究者兼エンジニアでいたいと思っています。
